Семантическое ядро для главной страницы. Составление семантического ядра от а до я. Бесплатные инструменты составления СЯ
Статья о том, как составить семантическое ядро самостоятельно, чтобы ваш интернет-магазин был на первых позициях выдачи поисковых систем. Процесс подбора ключевых слов – не такой уж и простой. Он потребует внимательности и относительно много времени. Но если вы готовы двигаться вперед и развивать свой бизнес, эта статья для вас. В ней подробно рассказывается о методах сбора ключевых слов, а также о том, какие именно инструменты могут вам помочь в этом.

Ответ банален - чтобы сайт «полюбили» поисковые машины. И чтобы при запросе пользователей по конкретным ключевым словам выдавали именно ваш ресурс.
И формирование семантического ядра – первый, но весьма важный и уверенный шаг на пути к цели!
Следующий шаг – создание своеобразного скелета, что подразумевает под собой распределенных подобранных «ключей» по определенным страницам сайта. И лишь после этого следует переходить на новый уровень – написания и внедрения статей, тегов.
Отметим, что в сети представлено несколько вариантов определения понятия семантического ядра (далее – СЯ).
В целом они сходны и если обобщить все, то можно сформировать следующее: набор ключевых слов (а также сопутствующих словосочетаний и форм) для продвижения сайта. Такие слова точно характеризуют направленность сайта, отображают интересы пользователей и соответствуют деятельности компании.
В нашей статье приведен пример формирования СЯ для интернет-магазина постельного белья. Весь процесс разделен на пять последовательных этапов.
1) Собираем базовые запросы
В данном случае речь идет обо всех фразах, которые будут соответствовать направлению деятельности магазина. Поэтому так важно максимально точно продумать те фразы, что наилучшим образом характеризуют товары, представленные в каталоге.
Конечно, сделать это иногда бывает непросто. Но на помощь придет правая графа Wordstat.Yandex – в ней указываются словосочетания, которые чаще прочих вводятся пользователями при использовании выбранной вами фразы.
Посмотрите видео по работе с Wordstat (всего 13 мин)
Для того чтобы получить результаты, введите в строке сервиса нужное вам словосочетание и кликните по кнопке «Подобрать».

Дабы не копировать все запросы вручную, рекомендуем использовать расширение Wordstat Helper, созданное специально для браузеров Mozilla Firefox и Google Chrome. Такое дополнение существенно упростит работу с подбором слов. Как оно работает – смотрите на скрине ниже.

Отобранные слова сохраните в отдельном документе. После проведите мозговой штурм и добавьте в него те фразы, которые придумаете.
2) Как расширить СЯ: три варианта
Первый этап относительно простой. Хотя и потребует от вас внимательности. Но второй – активной мозговой деятельности. Ведь каждая отдельно выбранная фраза – это основа будущей группы поисковых запросов, по которым вы будете продвигаться.
Чтобы собрать такую группу, необходимо использовать:
- синонимы;
- перефразирования.
Чтобы не «загрузнуть» в этом этапе, воспользуйтесь специальными приложениями или сервисами. Как это сделать – подробно описано ниже.
Как расширить СЯ с помощью планировщика ключевых слов Google
Переходим в тематический раздел (он называется Планировщик ключевых фраз) и набирает те фразы, которые наиболее точно характеризуются интересующую вас группу запросов. Прочие параметры не трогаете и кликаете по кнопке «Получить … ».

После этого просто скачиваете полученные результаты.

Как расширить СЯ с помощью Serpstat (ex. Prodvigator)
Вы также можете использовать другой подобный сервис, с помощью которого проводит анализ конкурентом. Ведь именно конкуренты представляют собой оптимальное место, где можно получить требуемые вам ключевые слова.
Сервис Serpstat (ex. Prodvigator) позволяет точно определить, по каким именно ключевым запросам ваши конкуренты выбились в лидеры поисковых систем. Хотя есть и другие сервисы – каким именно пользоваться, решайте сами.
Для того чтобы подобрать поисковые запросы, вам нужно:
- ввести один запрос;
- указать интересующий вас регион продвижения;
- кликнуть по кнопке «Поиск»;
- а когда он завершится – выбрать опцию «Поисковые запросы».

После этого кликните по кнопке «Экспорт таблицы».
Как составить семантическое ядро: как расширить СЯ с помощью Key Collector/Словоёб
У вас большой магазин с огромным количеством товаров? В такой ситуации вам понадобится сервис Key Collector .
Хотя если вы только начинаете познавать науку подбора ключевых слов и формирования семантического ядра, рекомендуем обратить внимание на другой сервис – с неблагозвучным названием Словоеб . Его преимущество состоит в том, что он полностью бесплатный.
Скачайте приложение, перейдите в настройки Яндекс.Директ и введите логин/пароль от почтового ящика Яндекса.

После этого:
- откройте новый проект;
- кликните по вкладке Данные;
- там нажмите на опцию Добавить фразы;
- укажите интересующий вас регион продвижения;
- введите запросы, которые были сформированы ранее.

После этого приступайте к сбору СЯ из Wordstat.Yandex. Для этого:
- перейдите в раздел «Сбор данных»;
- затем – нужно выбрать раздел «Пакетный сбор слов из левой колонки»;
- перед вами на экране появится новое окно;
- в нем – сделайте так, как указано на скрине ниже;

Отметим, что Key Collector отличный инструмент для объемных, крупных проектов и с его помощью легко организовать сбор статистических данных по сервисам, анализирующим «работу» сайтов-конкурентов. Например, к таковым сервисам относятся следующие: SEMrush, SpyWords, Serpstat (ex. Prodvigator) и многие другие.
3) Удаляем лишние «ключи»
Итак, база сформирована. Объем собранных «ключей» — более чем солидный. Но если их проанализировать (в данном случае – просто внимательно почитать), выясниться, что далеко не все собранные слова точно соотносятся с тематикой вашего магазина. А потому по ним на сайт будут заходиться «не целевые» пользователи.
Такие слова нужно удалять.
Представляем еще один пример. Так, на сайте вы продаете постельное белье, но в вашем ассортименте нет просто ткани, из которой такое белье можно пошить. Поэтому, все, что касается тканей – нужно убирать.
Кстати, полный перечень таких слов придется формировать вручную. Тут уже никакая «автоматика» не поможет. Естественно, потребуется относительно много времени и чтобы ничего не пропустить, рекомендуем устроить полноценный мозговой штурм.
Отметим следующие виды и типы слов, которые будут неактуальны для интернет-магазинов:
- название и упоминание магазинов-конкурентов;
- города и регионы, в которых вы не работаете и куда не поставляете товары;
- все слова и фразы, в которых присутствуют «бесплатно», «старый» или «б у», «скачать» и т.п.;
- название бренда, который не представлен в вашем магазине;
- «ключи», в которых имеются ошибки;
- повторяющиеся слова.
Теперь расскажем, как удалить все ненужные вам слова.
Сформируйте список
Открываем сервис Словоеб, в нем выбираем раздел «Данные», а там переходим во вкладку «Стоп-слова» и «вбейте» в нее отобранные вручную слова. Интересно, что записать слова можно, как вручную, так и просто подгрузить файл с ними (если вы таковой подготовили).

Таким образом, вы сможете довольно быстро устранить из своего списка стоп-слова, не отвечающие тематике, особенностям магазина.
Как составить семантическое ядро: быстрый фильтр
Вы получили своеобразную заготовку СЯ. Тщательно проанализируйте ее и приступайте к удалению ненужных слов вручную. Оптимизировать решение данной задачи поможет тот же сервис Словоеб. Вот последовательность действий, которые вам нужно выполнить:
- возьмите первое ненужное слово из вашего списка, к примеру, пусть это будет город Киев;
- вбейте его в поиск (на скрине – цифра 1);
- пометьте соответствующие строки;
- нажимая на них правой кнопкой мышки, удалите;
- нажмите Enter в поле поиска, дабы возвратиться к изначальному списку.

Повторяйте перечисленные действия столько, сколько придется, пока не пересмотрите наиболее возможный список слов.
4) Как составить семантическое ядро: группируем запросы
Дабы понимать, каким образом проводить распределение слов по конкретным страницам, следует выполнить группировку всех отобранных вами запросов. Для этого следует сформировать так называемые семантические кластеры.
Под данным понятием подразумевается группа схожих по тематике, смыслу «ключей», которая оформляется в виде многоуровневой структуры. Допустим, кластер первого уровня – это поисковый запрос «постельное белье». А вот кластерами второго уровня будут поисковые запросы «одеяла», «пледы» и тому подобное.
В большинстве случаев определение кластеров осуществляется при мозговом штурме. Но важно отлично разбираться в ассортименте, особенностях своего товара, но также учитывать и то, каким образом построена структура конкурентов.
Следующее, на что нужно обязательно обратить особое внимание – на последнем уровнем кластера должны быть только те запросы, которые точно соответствуют единственной потребности потенциальных клиентов. То есть, конкретному виду товаров.
Тут вам на помощь снова придет все тот же сервис Словоеб и описанная выше опция Быстрого фильтра. Он поможет выполнить сортировку поисковых запросов по определенным категориям.
Чтобы выполнить такую сортировку вам нужно выполнить несколько простых шагов. Сначала в поисковой строке сервиса вводите ключевое слово, которое будет использоваться при наименовании:
- категории;
- посадочной страницы и т.д.
Например, это может быть бренд постельного белья. В полученных результатах пометьте фразы, которые подходят вам и скопируйте.
Те фразы, что вам не нужны, просто выделите правой кнопкой мыши и удалите.

В правой части меню сервиса сделайте новую группу, назвав ее соответствующим образом. Например, наименованием бренда.
Чтобы перенести выбранные вами фразы в эту часть вкладки, необходимо выбрать строку Данные и кликнуть по надписи Добавить фразы. Подробнее – смотрите скрин.

Нажав Enter в графе поиска, вы возвратитесь к изначальному списку слов. Проделайте описанную процедуру со всеми остальными запросами.
Все отобранные фразы система будет выдавать в алфавитной последовательности, что упрощает работу с ними – вы легко сможете определить, что именно можно удалить. Или же сгруппировать слова в определенную группу.

Добавим, что ручная группировка также требует достаточное количество времени. Особенно, если речь идет о слишком большом количестве ключевых фраз. Поэтому рекомендуем воспользоваться автоматизированными платными программами. К таковым относятся:
- Key Collector;
- Rush-Analytics;
- Just-Magic и другие.
Также имеется полностью бесплатный скрипт Devaka.ru. Кстати, обратите внимание, что часто приходится объеденять некоторые типы запросов.
Поскольку нет никакого смысла нагромождать на сайте огромное число категорий, отличающихся только такими названиями, как «Красивое постельное белье» и «Модное постельное белье».
Чтобы определиться с важностью каждой отдельной ключевой фразы для той или иной категории, достаточно просто перенести их в планировщик Google, как показано на скрине.

Таким образом, вы сможете определить, насколько востребован тот или иной поисковый запрос. Все их можно разделить на три категории, в зависимости от частности использования:
- высокочастотные;
- низкочастотные;
- среднечастотные;
- и даже микро-низкочастотные.

Однако важно понимать, что точных цифр, которые отображают принадлежность запроса к определенной группе, нет. Здесь следует ориентироваться на тематику, как самого сайта, так и запроса. В отдельном случае запрос с частотой до 800 в месяц может считаться низкочастотным. В другой же ситуации запрос с частотой до 150 будет являться высокочастотным.
Самые высокочастотные запросы из всех отобранных впоследствии будут вписаны в теги. А вот самые низкочастотные рекомендовано использовать для того, чтобы оптимизировать под них конкретные страницы магазина. Поскольку среди таких запросов будет низкая конкуренция, хватит просто наполнить такие подразделы качественными текстовыми описаниями, дабы страницы оказалась в первых рядах поисковой выдачи.
Все перечисленные выше действия позволят вам сформировать четкую структуру, в которой будут иметься:
- все необходимые и важные категории – чтобы сделать визуализацию «скелета» вашего магазина, воспользуйтесь дополнительным сервисом XMind ;
- посадочные страницы;
- страницы, в которых представлена важная для пользователя информация – например, с контактными данными, с описанием условий доставки и т.д.
Как расширить семантическое ядро: альтернативный метод
С развитием сайта, расширением магазина будет увеличиваться и СЯ. Для этого необходимо проводить мониторинг и сбор ключевых фраз в рамках каждой группы. Что существенно упрощает и ускоряет процесс расширения СЯ.
Для сбора схожих запросов, для подсказки, воспользуйтесь дополнительными сервисами, среди которых:
- Serpstat (ex. Prodvigator);
- Ubersuggest;
- Keyword Tool;
- и прочие.
Ниже на скрине представлено, как пользоваться сервисом Продвигатор.

Как составить семантическое ядро: что делать после прохождения нашей инструкции
Итак, чтобы самостоятельно сформировать СЯ для интернет-магазина, вам необходимо выполнить целый ряд последовательных действий.
Начинается все с подбора ключевых слов, которые только могут использоваться при поиске ваших товаров и которые впоследствии станут основной группой запросов. Далее, воспользовавшись инструментами поисковых систем расширить семантическое ядро. Также для этого рекомендуется провести анализ сайтов-конкурентов.
Следующие шаги будут такими:
- анализ всех отобранных поисковых запросов;
- удаление запросов, которые не соответствуют смыслу вашего магазина;
- группирование запросов;
- формирование структуры сайта;
- постоянное отслеживание поисковых запросов и расширение СЯ.
Представленный в данной статье способ подбора СЯ для интернет-магазина – далеко не единственный верный и правильный. Существуют и другие. Но мы постарались представить вам наиболее удобный способ.
Естественно, для продвижения также важны такие показатели, как качество текстовых описаний, статей, тегов, структуры магазина. Но об этом мы поговорим в отдельном материале.
Чтобы не пропустить новые и полезные статьи, обязательно подпишитесь на нашу рассылку!
Вы еще не проходите тренинг, ? Запишитесь прямо сейчас и уже через 4 дня у вас будет свой сайт.
Если вы не сможете сделать его сами, мы сделаем его за вас!
Семантическое ядро – это множество ключевых слов, которые вводят в поисковую строку пользователи поисковых систем чтобы найти ответ на свой запрос.
Сбор семантического ядра необходим для того, чтобы найти все ключевые слова и фразы, по которым компания или сайт готова дать исчерпывающий ответ, удовлетворить потребность клиентов и по которым пользователи ищут (формулируют запрос) ответ на свой вопрос. Если у нас есть ключево слово, то пользователь попадет к нам на сайт, если нет — не попадет.
Объем ключевых слов в семантическом ядре зависит от целей, задач, особенностей бизнеса. От объема и глубины семантического ядра зависит охват целевой аудитории ее конверсия и стоимость. Полная семантика позволяет увеличить охват и снизить конкурентность.
Цели сбора семантического ядра
Поиск и подбор ключевых слов является одним из этапов электронного маркетинга. И сильно влияющего на дальнейший успех. На основании составленного семантического ядра будут разрабатываться:
- Сайт:
- «Идеальная» структура сайта, интернет-магазина, блога. Существуют 2 подхода к этому вопросу: SEO (search engine optimization) и PR (public relations). SEO подход заключается в первичном сборе всех ключевых запросов. Охватив максимальное количество ключевых слов ниши, мы разрабатываем структуру сайта, учитывая реальные запросы пользователей, их потребности. При PR способе сначала разрабатывается структура сайта на основе информации, которую мы хотим донести до пользователей. После собираются ключевые слова и разносятся по нашей структуре. Какую стратегию выбрать зависит от целей: если нужно в чем-то убедить, донести какую-то позицию и т.п., то выбирается PR способ. Если нужно получить как можно больше трафика, например, если делаем информационный сайт или интернет-магазин, то можно выбрать первый способ. А в целом, это фундамент для будущего продвижения: качественно проработанная структура сайта позволяет удобно сортировать информацию для пользователей (положительный пользовательский опыт) и возможность производить индексацию поисковым системам. Критериями принятия будущей структуры сайта являются цели и ожидания пользователей и результаты анализа успешных конкурентов.
- Стратегия лидогенерации:
- стратегия SEO . Определив поисковые запросы с наименьшей конкуренцией и наибольшим потенциальным трафиком, которые они могут принести, разрабатывается контентная стратегия по наполнению и оптимизации сайта.
- контекстная реклама . При проведении рекламных контекстных кампаний в Яндекс Директ, Google Ads и т.п. собирается максимальное количество релевантных ключевых слов, по которым мы можем и готовы удовлетворить спрос.
- карта информационных потребностей (контентный план). Имея сгруппированные ключевые слова по интентам (намерениям) пользователей составляется и выдается техническое задание копирайтерам на написание статей.
Исследование процесса поиска в поисковых системах
Психология поиска в интернете
Люди мыслят не словами. Слова — условные обозначения, через которые мы передаем свои мысли. Механизм трансформации мыслей в слова у каждого свой, каждый человек имеет свою особенность формулировать вопросы. Каждый запрос, введенный в строку поиска поисковой системы, человек сопровождает определенными мыслями и ожиданиями.
Если понять как люди ищут в интернете, то можно увязать свои маркетинговые мероприятия с их интересами. Зная как происходит поисковый процесс мы подбираем соответствующие ключевые слова и оптимизируем сайт, настраиваем контекстную рекламу.
После того, как пользователь ПС нажал на кнопку “Найти”, появившиеся поисковые результаты должны соответствовать его ожиданиям. Другими словами, результаты поиска (поисковая выдача и объявления контекстной рекламы) должны помочь решить вопрос пользователя. Следовательно, задача маркетолога настроить рекламное объявление и поисковый сниппет так, чтобы они были релевантны поисковому запросу.
- отражать поисковый запрос;
- учитывать стадия покупательского цикла.
Т.е. те слова, которые будут указаны в сниппетах и объявлениях, заложат основу ожиданий пользователя от вашего сайта. Следовательно, целевая страница, на которую он попадет кликнув по ссылке, должна соответствовать его ожиданиям. Оправдывая эти ожидания, мы увеличиваем вероятность положительного исхода. Реклама должна вести пользователя туда, где он сразу получит ответ.
Категории поисковых запросов:
- напрямую сформулированные (токарный станок по металлу, стоматолог);
- описание проблемы (чем выточить вал, болит зуб);
- симптомы проблемы (не работает коробка подачи токарного станка, раскрошился зуб);
- описание происшествия (хруст во время точения на токарном станке тв-16);
- название продукта, артикула, бренда, производителя.
Если внимательно изучить ключевые слова, то можно докопаться до сути проблемы: во время точения на токарном станке в коробке подач сломалась шестерня, поэтому мы можем предложить изготовить ее или предложить новый станок. Так как человек не лечил больной зуб и он раскрошился из-за кариеса, мы, как стоматология, предложим поставить имплант.
Классификация и типы поисковых запросов
По виду поиска:
- информационные – запросы по поиску информации, например, «скорость света», «как сделать удочку своими руками», «почему земля круглая» и т.д.;
- навигационные – запросы, по которым пользователи ищут организацию, бренд, человека и т.п. Например, «Coca-cola», «ресторан «Пяткин», «Лев Толстой»;
- транзакционные – запросы, вводимые пользователями при намерениях совершить какое-либо целевое действие. Например, «купить телефон Samsung Galaxy S6», «скачать онлайн книгу «Веб-аналитика на практике»;
- нечеткие запросы – все запросы, которые нельзя однозначно отнести к одному из вышеописанных типов, т.е. определить четко что именно ищет пользователь. Например, «Мейн кун» – не понятно, что хочет пользователь: узнать, что это за порода кошек или ищет где купить, а возможно еще что-то.
По геозависимости:
- геозависимые – запросы, зависимые от местонахождения пользователя. Например, «продуктовые магазины», «шиномонтаж в центре».
- геонезависимые – не зависят от месторасположения человека. Например, «рецепт котлет», «как установить сигнализацию».
По естественности:
- естественные – запросы, вводимые пользователями на естественном человеческом языке: «цены на ноутбуки самсунг», «характеристики рычажных ножниц»;
- телеграфные – запросы, вводимые на «телеграфном языке»: «ноутбуки самсунг цены», «рычажные ножницы характеристики».
По сезонности:
- сезонные – ключевые слова чувствительные ко времени. Такими запросами являются «зимние шины», «новогодний салют», «пасхальные яйца» и т.п.
- несезонные – ко времени никак не чувствительны, они популярны в любое время года. Примерами таких запросов являются: «наручные часы», «как приготовить пиццу», «установить винду».
По частотности:
- ВЧ – высокочастотные запросы.
- СЧ – среднечастотные запросы.
- НЧ – низкочастотные запросы.
- «Длинный хвост» (long tail) – микрочастотные поисковые запросы, как правило, состоящие из 4 и более слов и имеющие частотность 1-3 в месяц. Общий объем таких запросов дает в сумме ощутимый трафик с наименьшей конкуренцией в выдаче и практически без особых усилий в продвижении.
Сказать конкретно, что какое-то количество запросов соответствует высокочастотному запросу, а какое низкочастотному – нельзя, так как от ниши к нише эти значения сильно разнятся. Где-то 1000 запросов в месяц могут соответствовать низкочастотному запросу, а в другой нише он будет высокочастотным.
Значения частотности ключевых слов являются условными и предназначены для ранжирования по популярности.
По конкурентности:
- ВК – высококонкурентные запросы.
- СК – среднеконкурентные запросы.
- НК – низкоконкурентные запросы.
Данная классификация позволяет составить список первоочередных ключевых запросов, по которым будет проводится поисковое продвижение. Кроме того, снизить стоимость клика в контекстных рекламных компаниях.
Общие цели пользователя, веб-мастера и поисковой системы
В процессе поиска информации через поисковую систему участвуют 3 стороны: поисковая система, пользователь и веб-ресурс. И каждая из сторон имеет свои цели: пользователю нужно найти ответ на свой запрос, а поисковой системе и веб-ресурсу заработать на этом.
Если вебмастера начинают каким-либо образом манипулировать работой ПС, при этом не давая требуемых ответов пользователям, то проигрывают все: пользователь не получает ответ на свой запрос и уходит искать в другую поисковую систему на другом сайте.
Следовательно, первичны потребности пользователей, т.к. без них не заработает ни ПС, ни веб-ресурс. В первую очередь удовлетворяя интересы пользователей ПС мы способствуем общему заработку. Поисковая система заработает на контекстной рекламе, веб-ресурс – на продажах товаров или услуг самим пользователям или рекламодателям. Все в выигрыше. Связывайте ваши цели с целями пользователей. Тогда вероятность положительного исхода резко возрастает.
Исследование ключевых слов
Как мы уже выяснили, ключевые слова — это выраженные в словесной форме мысли. Наша цель — выбрать ключевые слова, отражающие мысли потребителей и спрос по которым мы можем удовлетворить. Если у нас есть ключево слово, то пользователь увидит наше сообщение, если нет — не увидит.
Одни ключевые слова генерируют большой трафик, другие — маленький. Одни дают высокую конверсию, другие генерируют низкокачественный трафик.
Каждое ключевое слово составляет отдельный субрынок со своей клиентурой. За каждой ключевой фразой скрывается некие нужда, желание, вопрос или предложение, которое человек может и не осознавать.
Определив к какой стадии покупательского цикла относится ключевое слово мы поймем когда и для чего пользователь ищет его, следовательно, предоставим актуальную для него информацию, соответствующую ожиданиям.
Прежде чем начать свое исследование задайте себе следующие вопросы:
- Какие ключевые слова нам нужно использовать, чтобы добраться до своей целевой аудитории?
- Какие ключевые фразы используют интересные нам сегменты клиентов при поиске наших продуктов?
- Что происходит в голове пользователя при написании этого запроса?
- На каком покупательском цикле они находятся, используя эту ключевую фразу?
Цели исследования ключевых слов
- Получить представления о существующей “экосистеме” и выработать стратегию естественного и оплаченного поиска.
- Выявить потребности потенциальных клиентов и выработать на них соответствующую реакцию.
Анатомия запросов
Ключевые фразы состоят из 3-х элементов:
[тело]+[спецификатор]+[хвост],
где тело (также его называют “маской”) — это основа запроса, только лишь по которому невозможно понять намерения пользователей; спецификаторы определяют намерения пользователей и относят запрос к транзакционным, информационным или навигационным; хвост только лишь детализирует намерения или потребность.
Например, токарный станок купить, фрезерный станок 6Р12 характеристики, купить ленточную пилу по металлу биметаллическую в мск.
Знание анатомии поисковых запросов позволяет собрать все маски при проработке семантики, а также правильно разнести собранные ключевые слова согласно покупательскому циклу при проработке стратегии оплаченного и естественного поиска.
Сегментирование ключевых слов
При поиске масок и проработке уже собранного семантического ядра появляется необходимость сегментировать ключевые слова для более удобной последующей работы. Имея сегментированные ключи мы понимаем как ищут люди, следовательно, расширяем их дополнительными ключевыми запросами, оцениваем вероятность продаж и работаем согласно стратегии. Каких-то определенных правил сегментирования не существует, т.к. семантика может сильно отличаться от ниши к нише.
Здесь я только лишь приведу некоторые примеры по каким признакам сегментируют ядра семантисты:
- по видам ключевых слов:
- прямой спрос — ищут то, что мы продаем, например, фрезерный станок;
- косвенный спрос — ищут фрезерный станок, а мы продаем фрезы к ним;
- ситуативный — затопили соседи, мы сделали ремонт;
- прочее — навигационные, витальные запросы.
- по объектам поиска:
- компания, объект (например, ремонтная бригада);
- продукт (ремонт фрезерных станков);
- производство, продажи (опт/розница) (изготовление запчастей для ремонта по чертежам);
- действие над объектом (пусконаладочные работы);
- специалист (инженер-коструктор);
- часть объекта, подуслуга (разработка конструкторской документации на запасные части к фрезерному станку).
- по ожидаемым чекам.
Long tail стратегия
Long-tail или концепция “длинного хвоста” была популяризирована в 2004 г. редактором журнала Wired Крисом Андерсоном. Суть концепции заключается в том, что компания продает редкие товары за счет широкого ассортимента на сумму большую чем бестселлеров.
Концепцию можно рассмотреть на примере книжной полки. Собственник магазина из-за ограниченности места будет стараться держать только товары, которые пользуются наибольшей популярностью. Если же мода на товар уже закончилась, то место книги занимает другая набирающая популярность.
В книжных интернет-магазинах полка не ограничена, в каталоге размещаются все доступные книги. Из проведенных исследований выяснилось, что благодаря широкому ассортименту объем продаж “непопулярных” книг превышает объем продаж бестселлеров. Эта концепция работает и в продажах музыки, фильмов, лекарственных препаратов и т.д., и само собой при составлении семантического ядра.
 Как из примера с книгами, ключевые поисковые фразы из “длинного хвоста” могут принести объем трафика превышающий объем трафика по высокочастотным запросам.
Как из примера с книгами, ключевые поисковые фразы из “длинного хвоста” могут принести объем трафика превышающий объем трафика по высокочастотным запросам.
Из практики long tail фразы обладают наибольшей конверсией, т.е. люди с наибольшей вероятностью находятся на этапе принятия решения о покупке.
Новые ключевые фразы
Если вы являетесь лидером мнений, имеете свою аудиторию и можете на нее влиять, попробуйте создавать новые ключевые поисковые фразы, вокруг которых будет строиться ваш контент. Если аудитория их подхватит, то вы первые будете выдаваться в поисковых результатах.
Сегментирование и воронка продаж
Сегментирование клиентов и ролевой принцип
Прежде чем собирать ключевые слова, компании нужно выяснить свою целевую аудиторию, сегменты и аватары своих клиентов. Чтобы было понятнее, сразу приведу пример: компания занимается продажей виброплит. Следовательно, ее целевой аудиторий будут строительные компании, а основными сегментами будут компании, осуществляющие дорожные работы, прокладку чего-либо под землей и т.д. Аватары — лица, принимающие решение о покупке и осуществляющие поиск товаров и услуг.
Здесь подробно на этом останавливать не будем.
Ролевой принцип заключается в том, что необходимо уделять внимание типу людей, которые могут искать ваш продукт, например, это может быть частное лицо, снабженец, инженер или генеральный директор. Люди, находящиеся в разных ролях могут употреблять различные ключевые слова. Поэтому, зная аватар своего клиента, учитываются его особенности поведения, ключевые слова подбираются с учетом требуемых ролей.
Например, если у вашей компании лицом, осуществляющим заказы, является инженер, то в его поисковых запросах могут встречаться специализированные технические термины.
Прежде чем начать нужно отметить, что у каждого бизнеса своя специфическая воронка продаж. Здесь рассматривается общая концепция. Состоит из 2-х частей: пропаганда и лояльность.

Этапы воронки продаж:
- Осведомленность — везде информировать о нашем продукте, чтобы люди узнали о нем. Данному этапу относятся ключевые слова обобщенного характера.
- Интерес — побудить потребителя задуматься как наш продукт сделает его жизнь лучше. На этом этапе транслируются выгоды и польза от продукта. Главная цель — вызвать желание получить продукт.
- Изучение — потребитель ищет информацию чтобы принять обоснованное решение: знакомиться с профессиональным жаргоном отрасли, в поисковых запросах появляются бренды, наименование специализированных услуг и т.п. Главная цель — максимально подробно донести выгоды и возможности продукта.
- Сравнение аналогов — потребитель сравнивает аналогичные продукты. Ключевые слова приобретают конкретный характер, указывая на наличие у потребителя определенного уровня знаний.
- Покупка — прежде чем принять решение о покупке покупатель изучает информацию о ценах, гарантиях, стоимости доставки, условиях обслуживания, возврата и т.д. Ключевые слова — низкочастотные запросы, запросы с продающими добавками.

Инструменты исследования ключевых слов
Алгоритм расширения ядра, сбор вложенных запросов
После того, как собраны все маски, переходим к сбору ключевых запросов вглубь.
Собирать вложенные запросы нужно для:
- написания релевантных объявлений под КС;
- выставления необходимой ставки для конкретного КС;
- установки релевантной ссылки в объявлении, ведущую на необходимую страницу.
Инструментами автоматизированными сбора вложенных запросов являются программное обеспечение, устанавливаемое на ПК, онлайн-сервисы, расширения для браузеров. Их достаточно много, но мы используем самый популярный — Key Collector — программа парсер ключевых слов и их частотностей, устанавливаемая на компьютер, а также позволяющая производить все необходимые мероприятия по сбору семантического ядра.
Желательно каждую смысловую группу парсить отдельно.
Алгоритм расширения будет следующий:
- парсинг масок в Яндекс Wordstat;
- парсинг масок в Google AdWords;
- парсинг масок в базе данных Букварикс;
- парсинг масок в базе данных Keys.so;
- выгрузка ключевых слов из Яндекс Метрики и Google Analytics;
- чистка и сбор частотностей ключевых слов;
- пакетный сбор поисковых подсказок;
- пакетный сбор похожих поисковых запросов из поисковой выдачи;
- чистка и сбор частотностей.
При помощи инструментов Яндекс Wordstat и Google AdWords мы получим основные ключевые поисковые фразы, имеющие частотность и популярность в поисковых системах. Букварикс, Keys.so, выгрузка КС из Яндекс Метрики и Google Analytics, поисковые подсказки и похожие поисковые запросы дадут также “хвостатые” слова пользователей.
Адаптация семантического ядра под контекстную рекламу
Алгоритм подготовки выглядит следующим образом:
- выбрать продающие ключевые слова;
- сегментировать КС;
- проработать минус-слова и минус-фразы;
- поставить операторы.
Ключевики для РСЯ и КМС подбираются немного по другому принципу в отличие от ключевых слов на поиске.
Выбор продающих ключевых слов
Из имеющегося списка ключевых фраз нам нужно понять что хочет человек (его потребности), какой ответ он хочет услышать на свой вопрос. Наша задача ответить в контексте поиска на те вопросы человека, которые интересны нам, т.е. выбрать те ключевые слова, которые с наибольшей вероятностью могут привести к конверсиям.
Кроме того, при помощи грамотного отбора КС мы снизим нецелевые показы, что повысить CTR и уменьшит цену клика.
Встречаются ситуации когда смысл запроса не понятен. Чтобы нам понять смысл того, что хотят большинство людей в таких случаях, необходимо вбить этот запрос в строку поисковой системы и посмотреть на результаты поиска. Благодаря машинному обучению и др. технологиям настройки поиска Яндекс и Google уже знают что хотят люди при каждом конкретном запросе. Остается только проанализировать результаты выдачи и принять правильное решение. Вторым способом является просмотр вложений словоформы в Яндекс Wordstat, третьим — додумать смысл, но пометить для дальнейшей проработки.
Полнота КС является одним из важных факторов, влияющих на успех рекламной компании. Следовательно, от качества проработки ключевых слов будет зависеть будущий результат. В контекстной рекламе нужно стремится не к объему СЯ, а к его качественной проработке.
В зависимости от целей, в дальнейшем можно воспользоваться стратегией: определить самые конверсионные запросы, протестировать их, а дальше масштабировать рекламную кампанию.
Сегментирование КС
Каких-то четких сегментов выделить нельзя, т.к. все различается от ниши к нише. В большинстве коммерческих сайтов можно сегментировать на основании этапов покупательского цикла. Или вы можете самостоятельно выделить какие-то сегменты, изучив свое ядро.
Основная задача сегментирования — способность в будущем легко управлять компанией: назначать ставки и бюджеты, быстро найти объявление и включить/остановить его показы и т.д.
Проработка минус-слов и фраз
Еще на этапе сбора семантического ядра у вас были собраны минус-слова и фразы. Остается адаптировать их под вашу рекламную компанию и провести кросс-минусовку.
Простановка операторов
Операторы применяются для ВЧ-запросов для избежания черной конкуренции, а также для экономии бюджета в высококонкурентной тематике и более точного формулирования фразы. Операторы можно комбинировать между собой.
Операторы Яндекс Директ
+слово — фиксация стоп-слов, вспомогательные части речи: предлоги, союзы, частицы, местоимения, числительные.
!слово — фиксация словоформы.
[слово1 слово2] — фиксация порядка слов.
-слово — исключение слова.
минус-фразы — исключение фразы, .
Операторы Google AdWords: типы соответствий ключевых слов
Широкий тип соответствия — используется по умолчанию, объявление будет показано по синониму, при опечатке, по похожим словосочетаниям и одинаковым интентам, например, по запросу “офисы в Москве” может показаться по ключевому слову “недвижимость Москва”.
Модификатор широкого соответствия — объявления покажутся по запросам, содержащим знак “+” и их близким вариантам (но не синонимам), расположенным в любом порядке. Например, + автомобиль + hyundai + tucsan.
Фразовое соответствие — объявление покажется по фразам, точно соответствующим ключевым словам или содержащие близкие слова. Чувствителен к порядку слов. Например, по запросу “цены монитор Benq” может показать объявление по ключевому слову “ монитор Benq ” .
Точное соответствие — объявление покажется по запросам точно соответствующим ключевому слово или его близким вариантам. Например, по запросу “шиномонтаж для грузовиков” может показаться объявление по ключевой фразе [ грузовой шиномонтаж ] .
Минус-слова — объявления будут показываться по запросам, не содержащим минус-слова.
Адаптация семантического ядра под поисковое продвижение (SEO)
Ядро нам понадобится для разработки четкой логической структуры сайта и полноты охвата тематики (опишем нашу тематику определенными ключевыми словами, характерными ей).
Алгоритм подготовки КС для SEO выглядит следующим образом:
- удалить из СЯ информационные запросы (оставить только коммерческие);
Кластеризация семантического ядра
Кластеризация — объединение запросов в группы на основе намерений пользователей, другими словами, необходимо объединить разные запросы в одну группу по которым человек ищет одно и тоже. Запросы распределяются в группы таким образом, чтобы их можно было продвигать на одной и той же странице (объединенные интентом пользователя).
Как пример, нельзя продвигать информационные и коммерческие запросы на одной странице. Более того, рекомендуется продвигать эти запросы на разных сайтах.
Например, спец. одежда — рабочая одежда, зиг машина — зиговка — зиговочный станок, циркулярная пила — круглопильный станок — распиловочный станок.
Кластеризация может быть:
- ручной — группировка происходит вручную в какой-либо специализированной программе или Excel. Человек, осуществляющий группировку просто обязан хорошо разбираться в теме, иначе ничего толкового не получится;
- автоматической — группировка происходит в автоматическом режиме на основе поисковой выдачи. Этот метод позволяет ускорить разгруппировку семантического ядра, состоящего из огромного количества ключевых фраз. Группировка имеет высокую точность (намного точнее, если вручную занимался человек, не разбирающийся в теме). Основным преимуществом данного способа является объединение в группы запросов только соответствующего типа, т.е.коммерческие и информационные не будут объедены в одну группу (хорошо иллюстрируют ситуацию запросы “смартфон” и “смартфоны”: 1-й — информационный и геонезависимый, 2-й — коммерческий и геозависимый, а вот “ноутбук” и “ноутбуки” — оба коммерческих и геозависимые);
- полуавтоматической — сначала создаются кластеры в автоматическом режиме, а после вручную до группироваться. Этот тип кластеризации объединяет как плюсы, так и минусы первых 2-х.
По виду кластеризация семантического ядра может быть:


Для коммерческих сайтов в большинстве случаев используется hard-кластеризация. В особых случаях можно использовать middle.
Карта релевантности
Карта релевантности необходима для планирования страниц и проработки структуры сайта. Основными элементами являются:
- наименование элемента дерева (категория, тег, страница и т.п.);
- наименование кластера;
- ключевые слова кластера;
- точная частота (“!ключевого!слова”);
- Title;
- Description;
- предыдущий Title;
- предыдущий H1;
- предыдущий Description.
Для визуализации структуры сайта часто прибегают к помощи mind-карт.

Адаптация семантического ядра под информационные сайты
Информационные запросы, если их рассматривать со стороны коммерческого использования, скорее относятся следующим к этапам воронки продаж осведомленности, интересу, изучению, сравнению аналогов. Т.е. ключевые слова напрямую не дают конверсии в продажи. Но на их основе мы можем информировать и влиять на принятие решения покупателя.
Если же речь идет о создании сайтов для заработка на рекламе, то необходимо специализироваться на определенной тематике и раскрыть ее полностью. Сайт должен отвечать на все вопросы по теме благодаря грамотной проработке всей семантики.
Алгоритм подготовки КС для информационных сайтов:
- удалить из СЯ коммерческие запросы (оставить только информационные);
- провести кластеризацию оставшегося СЯ;
- подготовить карту релевантности на основе получившихся кластеров.
Как видим, алгоритм принципиально ничем не отличается от работы по адаптации под SEO. Основной нюанс — тип кластеризации. Для информационных сайтов выбирают soft- или middle-кластеризацию.
Семантическое ядро под заказ
Стоимость семантического ядра определяется из расчета 3-7 руб. за ключевое слово. Так, кластеризованное семантическое ядро под SEO или инфосайт из 10 000 ключевиков будет стоить в среднем 50 000 руб. Плюс цена возрастет если нужно сегментировать ключевики под контекстную рекламу. Цена сильно зависит от качество проработки. Если вам предлагают дешевле указанных расценок, то следует как минимум задуматься почему. Ведь на хорошую проработку только масок порой уходит до 16 часов работы. Сэкономив на сборе семантического ядра (не охватите всей полноты и глубины тематики), потом потеряете на контекстной рекламе (будете показываться по самым конкурентным тематикам) и недополучите клиентов из поисковой выдачи.
Вот простейший пример качества проработки семантического ядра: при запросе «зиговочный станок» вы будете конкурировать в поисковой выдаче между 36 конкурентами, при запросе «зиговочные машины» — 27 конкурентами, а «зиговка» — только 8 конкурентами.
Запрос «Зиговочный станок»
Запрос «Зиговочная машина»
Здравствуйте, уважаемые читатели блога сайт. Хочу сделать очередной заход на тему «сбора семядра». Сначала , как полагается, а потом много практики, может быть и несколько неуклюжей в моем исполнении. Итак, лирика. Ходить с завязанными глазами в поисках удачи мне надоело уже через год, после начала ведения этого блога. Да, были «удачные попадания» (интуитивное угадывание часто задаваемых поисковикам запросов) и был определенный трафик с поисковиков, но хотелось каждый раз бить в цель (по крайней мере, ее видеть).
Потом захотелось большего — автоматизации процесса сбора запросов и отсева «пустышек». По этой причине появился опыт работы с Кейколлектором (и его неблагозвучным младшим братом) и очередная статья на тему . Все было здорово и даже просто замечательно, пока я не понял, что есть один таки очень важный момент, оставшийся по сути за кадром — раскидывание запросов по статьям.
Писать отдельную статью под отдельный запрос оправдано либо в высококонкурентных тематиках, либо в сильно доходных. Для инфосайтов же — это полный бред, а посему приходится запросы объединять на одной странице. Как? Интуитивно, т.е. опять же вслепую. А ведь далеко не все запросы уживаются на одной странице и имеют хотя бы гипотетический шанс выйти в Топ.
Собственно, сегодня как раз и пойдет речь об автоматической кластеризации семантического ядра посредством KeyAssort (разбивке запросов по страницам, а для новых сайтов еще и построение на их основе структуры, т.е. разделов, категорий). Ну, и сам процесс сбора запросов мы еще раз пройдем на всякий пожарный (в том числе и с новыми инструментами).
Какой из этапов сбора семантического ядра самый важный?
Сам по себе сбор запросов (основы семантического ядра) для будущего или уже существующего сайта является процессом довольно таки интересным (кому как, конечно же) и реализован может быть несколькими способами, результаты которых можно будет потом объединить в один большой список (почистив дубли, удалив пустышки по стоп словам).
Например, можно вручную начать терзать Вордстат , а в добавок к этому подключить Кейколлектор (или его неблагозвучную бесплатную версию). Однако, это все здорово, когда вы с тематикой более-менее знакомы и знаете ключи, на которые можно опереться (собирая их производные и схожие запросы из правой колонки Вордстата).
В противном же случае (да, и в любом случае это не помешает) начать можно будет с инструментов «грубого помола». Например, Serpstat (в девичестве Prodvigator), который позволяет буквально «ограбить» ваших конкурентов на предмет используемых ими ключевых слов (смотрите ). Есть и другие подобные «грабящие конкурентов» сервисы (spywords, keys.so), но я «прикипел» именно к бывшему Продвигатору.
В конце концов, есть и бесплатный Букварис , который позволяет очень быстро стартануть в сборе запросов. Также можно заказать частным образом выгрузку из монстрообразной базы Ahrefs и получить опять таки ключи ваших конкурентов. Вообще, стоит рассматривать все, что может принести хотя бы толику полезных для будущего продвижения запросов, которые потом не так уж сложно будет почистить и объединить в один большой (зачастую даже огромный список).
Все это мы (в общих чертах, конечно же) рассмотрим чуть ниже, но в конце всегда встает главный вопрос — что делать дальше . На самом деле, страшно бывает даже просто подступиться к тому, что мы получили в результате (пограбив десяток-другой конкурентов и поскребя по сусекам Кейколлектором). Голова может лопнуть от попытки разбить все эти запросы (ключевые слова) по отдельным страницах будущего или уже существующего сайта.
Какие запросы будут удачно уживаться на одной странице, а какие даже не стоит пытаться объединять? Реально сложный вопрос, который я ранее решал чисто интуитивно, ибо анализировать выдачу Яндекса (или Гугла) на предмет «а как там у конкурентов» вручную убого, а варианты автоматизации под руку не попадались. Ну, до поры до времени. Все ж таки подобный инструмент «всплыл» и о нем сегодня пойдет речь в заключительной части статьи.
Это не онлайн-сервис, а программное решение, дистрибутив которого можно скачать на главной странице официального сайта (демо-версию).

Посему никаких ограничений на количество обрабатываемых запросов нет — сколько надо, столько и обрабатывайте (есть, однако, нюансы в сборе данных). Платная версия стоит менее двух тысяч, что для решаемых задач, можно сказать, даром (имхо).
Но про техническую сторону KeyAssort мы чуть ниже поговорим, а тут хотелось бы сказать про сам принцип, который позволяет разбить список ключевых слов (практически любой длины) на кластеры, т.е. набор ключевых слов, которые с успехом можно использовать на одной странице сайта (оптимизировать под них текст, заголовки и ссылочную массу — применить магию SEO).
Откуда вообще можно черпать информацию? Кто подскажет, что «выгорит», а что достоверно не сработает? Очевидно, что лучшим советчиком будет сама поисковая система (в нашем случае Яндекс, как кладезь коммерческих запросов). Достаточно посмотреть на большом объеме данных выдачу (допустим, проаналазировать ТОП 10) по всем этим запросам (из собранного списка будущего семядра) и понять, что удалось вашим конкурентам успешно объединить на одной странице. Если эта тенденция будет несколько раз повторяться, то можно говорить о закономерности, а на основе нее уже можно бить ключи на кластеры.
KeyAssort позволяет в настройках задавать «строгость», с которой будут формироваться кластеры (отбирать ключи, которые можно использовать на одной странице). Например, для коммерции имеет смысл ужесточать требования отбора, ибо важно получить гарантированный результат, пусть и за счет чуть больших затрат на написание текстов под большее число кластеров. Для информационных сайтов можно наоборот сделать некоторые послабления, чтобы меньшими усилиями получить потенциально больший трафик (с несколько большим риском «невыгорания»). Как это сделать опять же поговорим.
А что делать, если у вас уже есть сайт с кучей статей, но вы хотите расширить существующее семядро и оптимизировать уже имеющиеся статьи под большее число ключей, чтобы за минимум усилий (чуток сместить акцент ключей) получить поболе трафика? Эта программка и на этот вопрос дает ответ — можно те запросы, под которые уже оптимизированы существующие страницы, сделать маркерными, и вокруг них KeyAssort соберет кластер с дополнительными запросами, которые вполне успешно продвигают (на одной странице) ваши конкуренты по выдаче. Интересненько так получается...
Как собрать пул запросов по нужной вам тематике?
Любое семантическое ядро начинается, по сути, со сбора огромного количества запросов, большая часть из которых будет отброшена. Но главное, чтобы на первичном этапе в него попали те самые «жемчужины», под которые потом и будут создаваться и продвигаться отдельные страницы вашего будущего или уже существующего сайта. На данном этапе, наверное, самым важным является набрать как можно больше более-менее подходящих запросов и ничего не упустить, а пустышки потом легко отсеяться.
Встает справедливый вопрос, а какие инструменты для этого использовать ? Есть один однозначный и очень правильный ответ — разные. Чем больше, тем лучше. Однако, эти самые методики сбора семантического ядра, наверное, стоит перечислить и дать общие оценки и рекомендации по их использованию.
- Яндекс Вордстат
и его аналоги у других поисковых систем — изначально эти инструменты предназначались для тех, кто размещает контекстную рекламу, чтобы они могли понимать, насколько популярны те или иные фразы у пользователей поисковиков. Ну, понятно, что Сеошники этими инструментами пользуются тоже и весьма успешно. Могу порекомендовать пробежаться глазами по статье , а также упомянутой в самом начале этой публикации статье (полезно будет начинающим).

Из недостатков Водстата можно отметить:
- Чудовищно много ручной работы (однозначно требуется автоматизация и она будет рассмотрена чуть ниже), как по пробивке фраз основанных на ключе, так и по пробивке ассоциативных запросов из правой колонки.
- Ограничение выдачи Вордстата (2000 запросов и не строчкой больше) может стать проблемой, ибо для некоторых фраз (например, «работа») это крайне мало и мы упускаем из вида низкочастотные, а иногда даже и среднечастотные запросы, способные приносить неплохой трафик и доход (их ведь многие упускают). Приходится «сильно напрягать голову», либо использовать альтернативные методы (например, базы ключевых слов, одну из которых мы рассмотрим ниже — при этом она бесплатная!).
- КейКоллектор
(и его бесплатный младший брат Slovoeb
) — несколько лет назад появление этой программы было просто «спасением» для многих тружеников сети (да и сейчас представить без КК работу над семядром довольно трудно). Лирика. Я купил КК еще два или три года назад, но пользовался им от силы несколько месяцев, ибо программа привязана к железу (начинке компа), а она у меня по нескольку раз в год меняется. В общем, имея лицензию на КК пользуюсь SE — так то вот, до чего лень доводит.

Подробности можете почитать в статье « ». Обе программы помогут вам собрать запросы и из правой, и из левой колонки Вордстата, а также поисковые подсказки по нужным вам ключевым фразам. Подсказки — это то, что выпадает из поисковой строки, когда вы начинаете набирать запрос. Пользователи часто не закончив набор просто выбирают наиболее подходящий из этого списка вариант. Сеошники это дело просекли и используют такие запросы в оптимизации и даже .
КК и SE позволяют сразу набрать очень большой пул запросов (правда, может потребоваться много времени, либо покупка XML лимитов, но об этом чуть ниже) и легко отсеять пустышки, например, проверкой частотности фраз взятых в кавычки (учите матчасть, если не поняли о чем речь — ссылки в начале публикации) или задав список стоп-слов (особо актуально для коммерции). После чего весь пул запросов можно легко экспортировать в Эксель для дальнейшей работы или для загрузки в KeyAssort (кластеризатор), о котором речь пойдет ниже.
- СерпСтат
(и другие подобные сервисы) — позволяет введя Урл своего сайта получить список ваших конкурентов по выдаче Яндекса и Гугла. А по каждому из этих конкурентов можно будет получить полный список ключевых слов, по которым им удалось пробиться и достичь определенных высот (получить трафик с поисковиков). Сводная таблица будет содержать частотность фразы, место сайта по ней в Топе и кучу другой разной полезной и не очень информации.

Не так давно я пользовал почти самый дорогой тарифный план Серпстата (но только один месяц) и успел за это время насохранять в Экселе чуть ли не гигабайт разных полезняшек. Собрал не только ключи конкурентов, но и просто пулы запросов по интересовавшим меня ключевым фразам, а также собрал семядра самых удачных страниц своих конкурентов, что, мне кажется, тоже очень важно. Одно плохо — теперь никак время не найду, чтобы вплотную заняться обработкой всей это бесценной информации. Но возможно, что KeyAssort все-таки снимет оцепенение перед чудовищной махиной данных, которые нужно обработать.
- Букварикс
— бесплатная база ключевых слов в своей собственной программной оболочке. Подбор ключевиков занимает доли секунды (выгрузка в Эксель минуты). Сколько там миллионов слов не помню, но отзывы о ней (в том числе и мой) просто отличные, и главное все это богатство бесплатно! Правда, дистрибутив программы весить 28 Гигов, а в распокованном виде база занимает на жестком диске более 100 Гбайт, но это все мелочи по сравнению с простотой и скоростью сбора пула запросов.

Но не только скорость сбора семядра является основным плюсом по сравнению с Вордстатом и КейКоллектором. Главное, что тут нет ограничений на 2000 строк для каждого запроса, а значит никакие НЧ и сверх НЧ от нас не ускользнут. Конечно же, частотность можно будет еще раз уточнить через тот же КК и по стоп-словам в нем отсев провести, но основную задачу Букварикс выполняет замечательно. Правда, сортировка по столбцам у него не работает, но сохранив пул запросов в Эксель там можно будет сортировать как заблагороссудится.
Наверное, еще как минимум несколько «серьезных» инструментов собора пула запросов приведете вы сами в комментариях, а я их успешно позаимствую...
Как очистить собранные поисковые запросы от «пустышек» и «мусора»?
Полученный в результате описанных выше манипуляций список, скорее всего, будет весьма большим (если не огромным). Поэтому прежде чем загружать его в кластерезатор (у нас это будет KeyAssort) имеет смысл его слегка почистить . Для этого пул запросов, например, можно выгрузить к кейколлектор и убрать:
- Запросы со слишком низкой частотностью (лично я пробиваю частотность в кавычках, но без восклицательных знаков). Какой порог выбирать решать вам, и во многом это зависит от тематики, конкурентности и типа ресурса, под который собирается семядро.
- Для коммерческих запросов имеется смысл использовать список стоп-слов (типа, «бесплатно», «скачать», «реферат», а также, например, названия городов, года и т.п.), чтобы заранее убрать из семядра то, что заведомо не приведет на сайт целевых покупателей (отсеять халявшиков, ищущих информацию, а не товар, ну, и жителей других регионов, например).
- Иногда имеет смысл руководствоваться при отсеве показателем конкуренции по данному запросу в выдаче. Например, по запросу «пластиковые окна» или «кондиционеры» можно даже не рыпаться — провал обеспечен заранее и со стопроцентной гарантией.
Скажите, что это слишком просто на словах, но сложно на деле. А вот и нет. Почему? А потому что один уважаемый мною человек (Михаил Шакин) не пожалел времени и записал видео с подробным описанием способов очистки поисковых запросов в Key Collector :
Спасибо ему за это, ибо данные вопрос гораздо проще и понятнее показать, чем описать в статье. В общем справитесь, ибо я в вас верю...
Настройка кластеризатора семядра KeyAssort под ваш сайт
Собственно, начинается самое интересное. Теперь весь этот огромный список ключей нужно будет как-то разбить (раскидать) на отдельных страницах вашего будущего или уже существующего сайта (который вы хотите существенно улучшить в плане приносимого с поисковых систем трафика). Не буду повторяться и говорить о принципах и сложности данного процесса, ибо зачем тогда я первую часть этой стать писал.
Итак, наш метод довольно прост. Идем на официальный сайт KeyAssort и скачиваем демо-версию , чтобы попробовать программу на зуб (отличие демо от полной версии — это невозможность выгрузить, то бишь экспортировать собранное семядро), а уже опосля можно будет и оплатить (1900 рубликов — мало, мало по современным реалиям). Если хотите сразу начать работу над ядром что называется «на чистовик», то лучше тогда выбрать полную версию с возможностью экспорта.
Программа КейАссорт сама собирать ключи не умеет (это, собственно, и не ее прерогатива), а посему их потребуется в нее загрузить. Сделать это можно четырьмя способами — вручную (наверное, имеется смысл прибегать к этому методу для добавления каких-то найденных уже опосля основного сбора ключей), а также три пакетных способа импорта ключей :
- в формате тхт — когда нужно импортировать просто список ключей (каждый на отдельной строке тхт файлика и ).
- а также два варианта экселевского формата: с нужными вам в дальнейшем параметрами, либо с собранными сайтами из ТОП10 по каждому ключу. Последнее может ускорить процесс кластеризации, ибо программе KeyAssort не придется самой парсить выдачу для сбора эти данных. Однако, Урлы из ТОП10 должны быть свежими и точными (такой вариант списка можно получить, например, в Кейколлекторе).
Да, что я вам рассказываю — лучше один раз увидеть:
В любом случае, сначала не забудьте создать новый проект в том же самом меню «Файл», а уже потом только станет доступной функция импорта:

Давайте пробежимся по настройкам программы (благо их совсем немного), ибо для разных типов сайтов может оказаться оптимальным разный набор настроек. Открываете вкладку «Сервис» — «Настройки программы» и можно сразу переходить на вкладку «Кластеризация» :

Тут самое важное — это, пожалуй, выбор необходимого вам вида кластеризации . В программе могут использоваться два принципа, по которым запросы объединяются в группы (кластеры) — жесткий и мягкий.
- Hard — все запросы попавшие в одну группу (пригодные для продвижения на одной странице) должны быть объединены на одной странице у необходимого числа конкурентов из Топа (это число задается в строке «сила группировки»).
- Soft — все запросы попавшие в одну группу будут частично встречаться на одной странице у нужного числа конкурентов и Топа (это число тоже задается в строке «сила группировки»).
Есть хорошая картинка наглядно все это иллюстрирующая:

Если непонятно, то не берите в голову, ибо это просто объяснение принципа, а нам важна не теория, а практика, которая гласит, что:
- Hard кластеризацию лучше применять для коммерческих сайтов . Этот метод дает высокую точность, благодаря чему вероятность попадания в Топ объединенных на одной странице сайта запросов будет выше (при должном подходе к оптимизации текста и его продвижению), хотя самих запросов будет меньше в кластере, а значит самих кластеров больше (больше придется страниц создавать и продвигать).
- Soft кластеризацию имеет смысл использовать для информационных сайтов , ибо статьи будут получаться с высоким показателем полноты (будут способны дать ответ на ряд схожих по смыслу запросов пользователей), которая тоже учитывается в ранжировании. Да и самих страниц будет поменьше.
Еще одной важной, на мой взгляд, настройкой является галочка в поле «Использовать маркерные фразы» . Зачем это может понадобиться? Давайте посмотрим.
Допустим, что у вас уже есть сайт, но страницы на нем были оптимизированы не под пул запросов, а под какой-то один, или же этот пул вы считаете недостаточно объемным. При этом вы всем сердцем хотите расширить семядро не только за счет добавления новых страниц, но и за счет совершенствования уже существующих (это все же проще в плане реализации). Значит нужно для каждой такой страниц добрать семядро «до полного».
Именно для этого и нужна эта настройка. После ее активации напротив каждой фразы в вашем списке запросов можно будет поставить галочку. Вам останется только отыскать те основные запросы, под которые вы уже оптимизировали существующие страницы своего сайта (по одному на страницу) и программа KeyAssort выстроит кластеры именно вокруг них. Собственно, все. Подробнее в этом видео:
Еще одна важная (для правильной работы программы) настройка живет на вкладке «Сбор данных с Яндекс XML» . вы можете прочитать в приведенной статье. Если вкратце, то Сеошники постоянно парсят выдачу Яндекса и выдачу Вордстата, создавая чрезмерную нагрузку на его мощности. Для защиты была внедрена капча, а также разработан спецдоступ по XML, где уже не будет вылезать капча и не будет происходить искажение данных по проверяемым ключам. Правда, число таких проверок в сутки будет строго ограничено.
От чего зависит число выделенных лимитов? От того, как Яндекс оценит ваши . можно перейдя по этой ссылке (находясь в том же браузере, где вы авторизованы в Я.Вебмастере). Например, у меня это выглядит так:

Там еще есть снизу график распределения лимитов по времени суток, что тоже важно. Если запросов нужно пробить много, а лимитов мало, то не проблема. Их можно докупить . Не у Яндекса, конечно же, напрямую, а у тех, у кого эти лимиты есть, но они им не нужны.
Механизм Яндекс XML позволяет проводить передачу лимитов, а биржи, подвязавшиеся быть посредниками, помогают все это автоматизировать. Например, на XMLProxy можно прикупить лимитов всего лишь по 5 рублей за 1000 запросов, что, согласитесь, совсем уж не дорого.
Но не суть важно, ибо купленные вами лимиты все равно ведь перетекут к вам на «счет», а вот чтобы их использовать в KeyAssort, нужно будет перейти на вкладку "Настройка " и скопировать длинную ссылку в поле «URL для запросов» (не забудьте кликнуть по «Ваш текущий IP» и нажать на кнопку «Сохранить», чтобы привязать ключ к вашему компу):

После чего останется только вставить этот Урл в окно с настройками KeyAssort в поле «Урл для запросов»:

Собственно все, с настройками KeyAssort покончено — можно приступать к кластеризации семантического ядра.
Кластеризация ключевых фраз в KeyAssort
Итак, надеюсь, что вы все настроили (выбрали нужный тип кластеризации, подключили свои или покупные лимиты от Яндекс XML), разобрались со способами импорта списка с запросами, ну и успешно все это дело перенесли в КейАссорт. Что дальше? А дальше уж точно самое интересное — запуск сбора данных (Урлов сайтов из Топ10 по каждому запросу) и последующая кластеризация всего списка на основе этих данных и сделанных вами настроек.
Итак, для начала жмем на кнопку «Собрать данные» и ожидаем от нескольких минут до нескольких часов, пока программа прошерстит Топы по всем запросам из списка (чем их больше, тем дольше ждать):

У меня на три сотни запросов (это маленькое ядро для серии статей про работу в интернете) ушло около минуты. После чего можно уже приступать непосредственно к кластеризации , становится доступна одноименная кнопка на панели инструментов KeyAssort. Процесс этот очень быстрый, и буквально через несколько секунд я получил целый набор калстеров (групп), оформленных в виде вложенных списков:

Подробнее об использовании интерфейса программы, а также про создание кластеров для уже существующих страниц сайта смотрите лучше в ролике, ибо так гораздо нагляднее:
Все, что хотели, то мы и получили, и заметьте — на полном автомате. Лепота.
Хотя, если вы создаете новый сайт, то кроме кластеризации очень важно бывает наметить будущую структуру сайта (определить разделы/категории и распределить по ним кластеры для будущих страниц). Как ни странно, но это вполне удобно делать именно в KeyAssort, но правда уже не в автоматическом режиме, а в ручном режиме. Как?
Проще опять же будет один раз увидеть — все верстается буквально на глазах простым перетаскиванием кластеров из левого окна программы в правое:
Если программу вы таки купили, то сможете экспортировать полученное семантическое ядро (а фактически структуру будущего сайта) в Эксель. Причем, на первой вкладке с запросами можно будет работать в виде единого списка, а на второй уже будет сохранена та структура, что вы настроили в KeyAssort. Весьма, весьма удобно.
Ну, как бы все. Готов обсудить и услышать ваше мнение по поводу сбора семядра для сайта.
Удачи вам! До скорых встреч на страницах блога сайт
Вам может быть интересно
Vpodskazke - новый сервис Вподсказке для продвижения подсказок в поисковых системах
SE Ranking - лучший сервис мониторинга позиций для новичков и профессионалов в SEO
Сбор полного семантического ядра в Топвизоре, многообразие способов подбора ключевых слов и их группировка по страницам
Практика сбора семантического ядра под SEO от профессионала - как это происходит в текущих реалиях 2018
Оптимизация поведенческих факторов без их накрутки
SEO PowerSuite - программы для внутренней (WebSite Auditor, Rank Tracker) и внешней (SEO SpyGlass, LinkAssistant) оптимизации сайта
 SERPClick: продвижение поведенческими факторами
SERPClick: продвижение поведенческими факторами
Шаг 2. Продолжаем расширять семантику, используя инструмент “Похожие фразы ”, который . Внедряя ключевики из этого отчета, вы максимально . А параметр “Сила связи” подскажет вам, используют ли эту фразу в своем семантическом ядре ваши конкуренты из топ-20. Чем выше число, тем больше сайтов используют исследуемую фразу и предложенный синоним.
Выраженный результат показывается на товарах, которые люди могут искать по-всякому. Например, подушки для спины.
Шаг 3. Последний шаг в расширении семантики - это сбор поисковых подсказок поисковой системы. Преимущество в том, что сервисы собирают информацию в режиме реального времени и вытаскивают сразу все поисковые подсказки, которые может предложить Яндекс/Google. Поисковики же предлагают только до 12 подсказок на фразу .


Чтобы выгрузить все подсказки, переходим в инструмент “Поисковые подсказки ” и выгружаем список.
Обратите внимание на облако популярных фраз, именно такие слова чаще всего ищут люди со словосочетанием “ортопедические матрасы”. Если среди фраз есть определенные размеры, бренды или тип изделия, то стоит включить их в ассортимент интернет-магазина.
Также под информационный тип ключевиков, как “лучшие матрасы для проблем с позвоночником”, вы можете подготовить статью к вам в блог, что станет дополнительным источником трафика и продаж .
Шаг 4. Сводим все отчеты в единую таблицу и чистим дубли с помощью плагина Remove Duplicate .


Потраченное время - до 5 минут. Зависит от количества ключевых запросов.
Пользуюсь сервисами вы уже выигрываете время перед теми, кто собирает, чистит и кластеризует семантику вручную . Чтобы понять разницу, попробуйте провести все описанные шаги, вытаскивая ключевые фразы и поисковые подсказки в Wordstat, а затем повторите инструкцию.
Кластеризация
Также экономит до 8 часов автоматическая кластеризация . Это разбивка всех ключевых фраз на смысловые группы, под которые создается структура сайта, фильтры, категории товаров и так далее.
Для этого загрузите ваш файл со всеми ключевыми фразами в инструмент кластеризации и в течение 10–30 минут , в зависимости от количества ключевиков, вы получите отчет .
Если группировка не удовлетворяет качеством, не выходя из проекта, щелкните по значку “настройки ” и поставьте силу связи сильнее/слабее. Изменение настроек в пределах одного проекта бесплатное, перегруппировка семантики длится не больше 1 минуты.
Этап 3. Автоматизация уровень профи
Если вы уже собираете семантику с помощью сервисов через интерфейс, пришло время познакомить вас с API. Это набор функций, позволяющих пользователям получать доступ к данным или компонентам сервиса, в нашем случае - Serpstat. Преимущество работы по API:

А теперь повторим все действия по сбору семантики со второго этапа с помощью API.
Шаг 1. Скопируйте эту таблицу со скриптом в свой Google Диск.
Шаг 2. Скопируйте свой токен в личном профиле Serpstat и вставьте в соответствующее поле в таблице. Также выберите нужную базу поисковика и заполните параметры отбора ключевых фраз, добавьте список ключевых фраз, по которым вы хотите выгрузить отчеты.

Запустите скрипт, парся по очереди отчеты по подбору фраз, поисковых подсказок и похожих/сленговых фраз (см. скрин):

Программа попросит залогиниться через gmail-аккаунт и запросит доступ на разрешение работы. Подтвердите запуск скрипта, минуя предупреждение о небезопасности.
Шаг 3.
Через 30–60 секунд скрипт завершит работу и соберет ключевые слова в рамках заданных параметров.

Также в этом скрипте можно настроить фильтр по минус-словам и любые другие.
Итого мы сэкономили еще несколько часов работы seo-специалиста на сведении всех отчетов в один и сборе данных по каждому ключевому слову в интерфейсе.
Скрипты для работы по API могут писать ваши seo-специалисты, а можно найти официальные в открытом доступе .
Выводы
Максимально ускоряют сбор семантического ядра без потери качества такие действия:
- Кластеризация с помощью специальных сервисов.
- Парсинг ключевых слов, подсказок и сленговых выражений по API seo-платформ.
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его вместе!
Небольшое предисловие
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
- мозговой штурм - анализ базовых фраз и подготовка парсинга
- парсинг - расширение базовой семантики на основе Вордстат и других источников
- отсев - отсев после парсинга
- анализ - анализ частотности, сезонности, конкуренции и других важных показателей
- доработка - групировка, разделение коммерческих и информационных фраз ядра
О наиболее важных этапах сбора и пойдет речь ниже!
ВИДЕО - составление семантического ядра по конкурентам
Мозговой штурм при создании семантического ядра — напрягаем мозги
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
- seo блог
- сео блог
- блог про сео
- блог про seo
- продвижение
- продвижение проекта
- раскрутка
- раскрутка
- продвижение блогов
- продвижение блога
- раскрутка блогов
- раскрутка блога
- продвижение статьями
- статейное продвижение
- miralinks
- работа в sape
- покупка ссылок
- закупка ссылок
- оптимизация
- оптимизация страницы
- внутренняя оптимизация
- самостоятельная раскрутка
- как раскрутить ресурс
- как раскрутить свой сайт
- как раскрутить сайт самому
- как раскрутить сайт самостоятельно
- самостоятельная раскрутка
- бесплатная раскрутка
- бесплатное продвижение
- поисковая оптимизация
- как продвинуть сайт в яндексе
- как раскрутить сайт в яндексе
- продвижение под яндекс
- продвижение под гугл
- раскрутка в гугл
- индексация
- ускорение индексации
- выбор донора сайту
- отсев доноров
- раскрутка постовыми
- использование постовых
- раскрутка блогами
- алгоритм яндекса
- апдейт тиц
- апдейт поисковой базы
- апдейт яндекса
- ссылки навсегда
- вечные ссылки
- аренда ссылок
- арендованные ссылке
- ссылки с помесячной оплатой
- составление семантического ядра
- секреты раскрутки
- секреты раскрутки
- тайны seo
- тайны оптимизации
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :
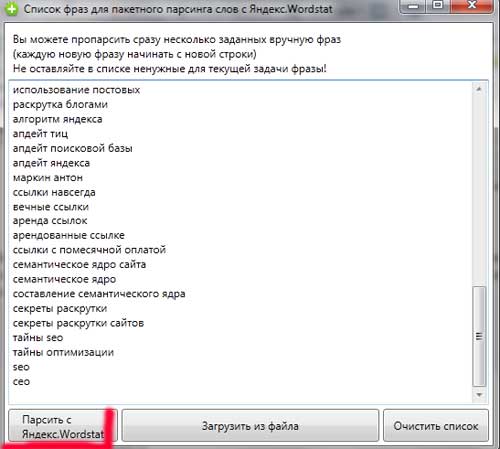
Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Чистка семантики
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:

Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
курсы поисковой оптимизации продам раскрученный сайт
Анализ семантического ядра
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Экспорт и группировка семантического ядра
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:

Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
- такие частотные запросы, как должны иметь намного больший хвост из менее частотных фраз, чем мы видим
- сео новости
- всплыл новый ключ, который мы не учли ранее — статьи сео . Необходимо проанализировать этот ключ
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
- лучший seo блог
- seo новости
- статьи seo
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
Финальный отсев
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:
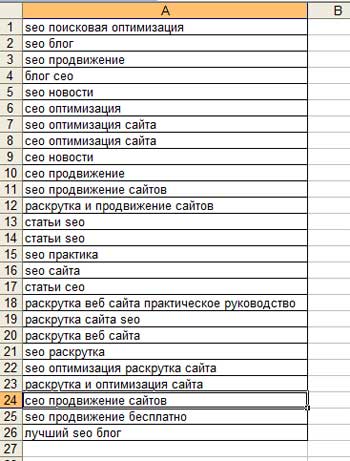

Затем проверяем стоимость получения одного перехода по нашим ключевым словам:

Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.

Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
Полезная информация!
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Кластеризация семантического ядра
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
- Подбор и анализ поисковых запросов
- Группировка запросов по страницам сайта (создание посадочных страниц)
- Подготовка seo текстов для посадочных страниц на основе группы запросов для этих страниц
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
- Один и тот же интент могут иметь несколько запросов не имеющих какой-либо семантической близости, например – “обслуживание автомобиля” и “записаться на ТО”
- Запросы, имеющие абсолютную семантическую близость могут содержать в себе кардинально разные интенты, например, хрестоматийная ситуация – “мобильник” и “мобильники”. В одном случае пользователь хочет купить телефон, а в другом посмотреть фильм
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
- Система поочередно вводит все поданные ей запросы в поисковую выдачу и запоминает результаты из ТОП
- После поочередного ввода запросов и сохранения результатов, система ищет пересечения в выдаче. Если один и тот же сайт одним и тем же документом (страница сайта) находится в ТОП сразу по нескольким запросам, то эти запросы теоретически можно объединить в одну группу
- Становится актуальным такой параметр, как сила группировки, который говорит системе, сколько именно должно быть пересечений, чтобы запросы можно было добавить в одну группу. К примеру, сила группировки 2 означает, что в выдаче по 2-м разным запросам должно присутствовать не менее двух пересечений. Говоря еще проще – минимум две страницы двух разных сайтов должны присутствовать одновременно в ТОП по одному и другому запросу. Пример ниже.
- При группировках больших семантики становится актуальна логика связей между запросами, на основе которой выделяют 3 базовых вида кластеризации: soft, middle и hard. О видах кластеризации мы еще поговорим в следующих записях этого дневника